
-huckleberry.jpg)
Typed ENV Vars for Valid Environments from Dev to Production
Tired of copying secrets into GitHub every other day? Chasing down correct values for newly introduced ENV vars after git pull? Today, we are introducing a solution to make these problems go away. Don't believe me? Read on.
Introducing the 🦉 Owl Store, a concrete implementation of a Type System for Environment Variables that specifies, resolves, and verifies your environment's correctness.
Let's Start With A Demo
The demo is a Poor Sebastian’s Vercel to generate preview URLs for Runme's documentation. Here is what it does:
- A Dagger module that leverages the Docusaurus build
- To generate production-ready Nginx container image with the docs
- Pushes the image to GCP’s artifact registry
- Launches a Google Cloud Run instance and returns the Preview URL
- Transparently uses the Owl Store to resolve the services accounts to auth the GCP operations
Check out this video:
You can run it yourself at home. It's self-contained using Dagger and requires minimal setup and a GCP account. It’s available inside Runme’s docs repo. All steps to get it up and running are documented in README.md, which is itself a Runme notebook. Be sure to switch to Runme's pre-release; otherwise, you won't see the Env Store panel.
Now, let's get into the details.
Why is this hard?
Getting environments “right” is no easy feat. Ask your developer: Docker, lock files, pipelines, and the elasticity of cloud computing resources have undoubtedly increased the reproducibility of environments across the software development lifecycle. Albeit with more tangible success in production(-like) environments. DevOps is all about the left shift; however, arguably, this shift is still miles apart from humans.
A tell-tale sign I often encounter when talking to engineers in the field is having separate engineers/teams owning Platform Engineering and DevX. The idea is to provide narrow git push interfaces to advance code out of development, which is resource-intensive enough to, at best, cover and support the critical path. It’s where uniformity of operational excellence (12factor) clashes with developers’ need for unconstrained creativity and experimentation.
Crossing the Dev vs. Ops Chasm
I have been pondering why we have yet to overcome the proverbial Dev vs. Ops chasm for several years now. During my time at Smallstep, I learned hands-on how powerful PKI-based strong identity (humans & workloads via OAuth & Workload Identity) is to moving to zero-trust security models (e.g., via mTLS or SSH certificates) that liberate us from reliance on the of space-bound perimeters (Hi, VPCs!) to enforce secure computing in the cloud-native age.
I have come to the firm belief that Configuration and Secrets Management is what's holding us back. This is not because we haven’t made strides with Sealed Secrets, CloudKMS, Vault, and a slew of Cloud-certified Secret Managers that provide sophisticated ACLing mechanisms.
It’s because we create JIRA tickets to generate, copy, and paste credentials to resources into GitHub/Gitlab or—close your 🙈 eyes and 🙉 ears now—paste them into Slack channels or Zoom chats. The available solutions aren’t rooted in strong cryptographic identity. They don't work the same for humans and workloads, which, if they did, would massively increase reproducibility and portability—unlocking Single Sign-On for Environments.
GitHub/Gitlab: Take My Bargaining Chips
This isn’t just time-intensive and error-prone; it makes third parties like GitHub, Gitlab, etc., our system of record. That’s something they love: more usage and more vendor lock-in. What an excellent way to give up all our bargaining chips. And now, we still haven’t solved the problem for developers in their environments, which requires bespoke solutions or running clusters locally. We wind up with spotty “project onboarding instructions,” which leave us with the challenge of figuring out how to draw the rest of the owl on our own—every time.
Enter the Owl Store 🦉
As a bourbon-drinking armchair Computer Scientist myself, I spent quite some time dreaming up a solution to switch into building it earnestly well over a year ago. While still experimental, it’s closer to a beta than an alpha. There is an immense amount of ground to cover, so delivering an end-to-end experience was more important to me than going deep on any particular part. There will be bugs!
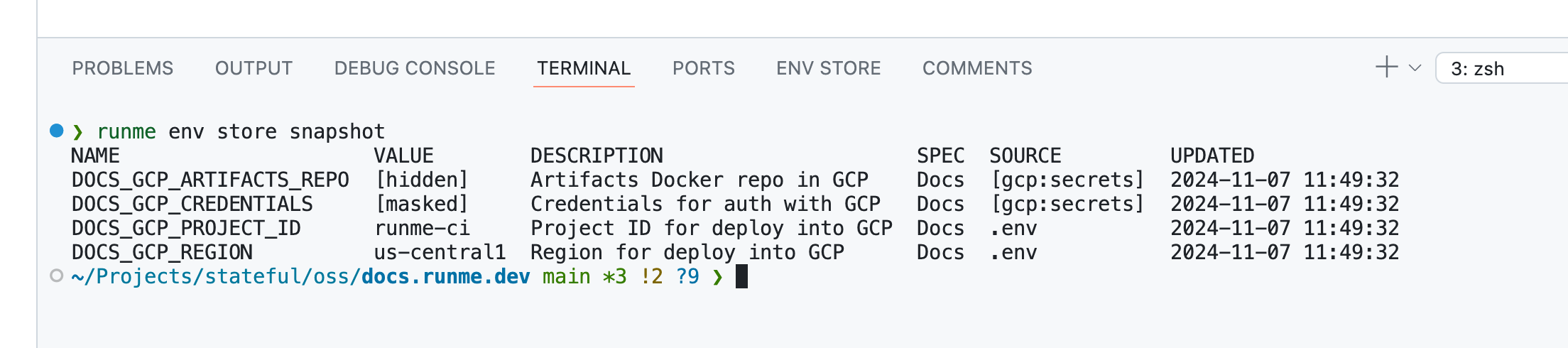
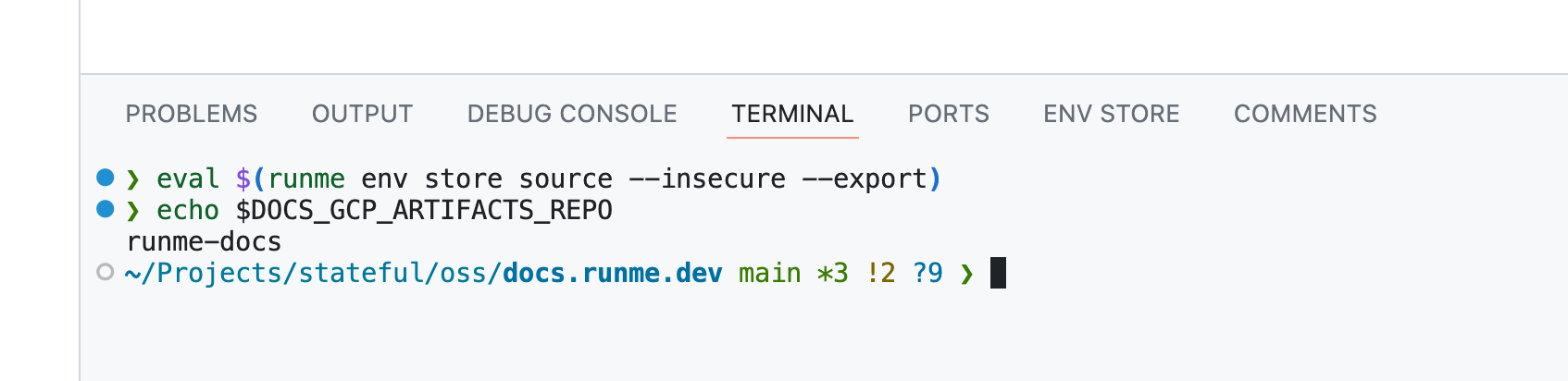
While the Owl Store is fully integrated into Runme’s DevOps notebooks (which works well for demos), it’s remarkably self-contained. Given enough interest, I would love to spin it out as a standalone project. It's got a rudimentary CLI interface, which even lets you source a session's ENV vars into a running terminal session:
A Complete Solution That's Unfinished
Please note that the Owl is a work in progress. While it illustrates a complete solution, it’s far from finished. Building it has helped unpack the series of unsolved problems along the way. The code is very pragmatic, prioritizing making it work and then making it right before making it concise/scaleable.
A warning: If you expect another “Kubernetes API”, the Owl Store isn’t that. However, I’d love a Kubernetes Admission Controller that mounts secrets downstream. Get in touch. I have also looked at various technologies, including DirEnv, Nix, Infisical, Doppler Labs, Vault, Chezmoi, Teller, Cuelang, and Pulumi, all solving parts of the problem, to name a few. My main objection (applicable to end-to-end solutions) is that users have to adopt them wholesale, more often than not, handing over custody of their secrets and/or requiring SDKs that circumvent the treasured environment altogether.
Blobs of KEY=VALUE Strings Running the World
Configuration and Secret Management are a “death by papercuts” issue. It’s not “just” secrets; it’s all of configuration. While secrets are exponentially more complex, they are still "configured". Nothing works if your configuration is wrong. This is why the Owl Store gets to the mother of all configuration management challenges: The Correctness of Environment Variables. Blobs of KEY=VALUE Strings are running the world!
Before debriefing the Owl’s implementation details, let's jump into an example. The goal is to paint a picture of how it works from a user’s perspective, using a sysadmin mindset and focusing on the Owl Store's visible parts that concern users.
Good Luck Running a Monolith Locally
Below is Stateful's Git repository containing the monolith running our Cloud product. With many third-party API integrations, the amount of environment configuration is substantial. However, 57 environment variables are actually on the low end for a monolith.
❌ Invalid Environment
The Owl Store's UX clearly identifies how “incomplete” my environment’s variables are.
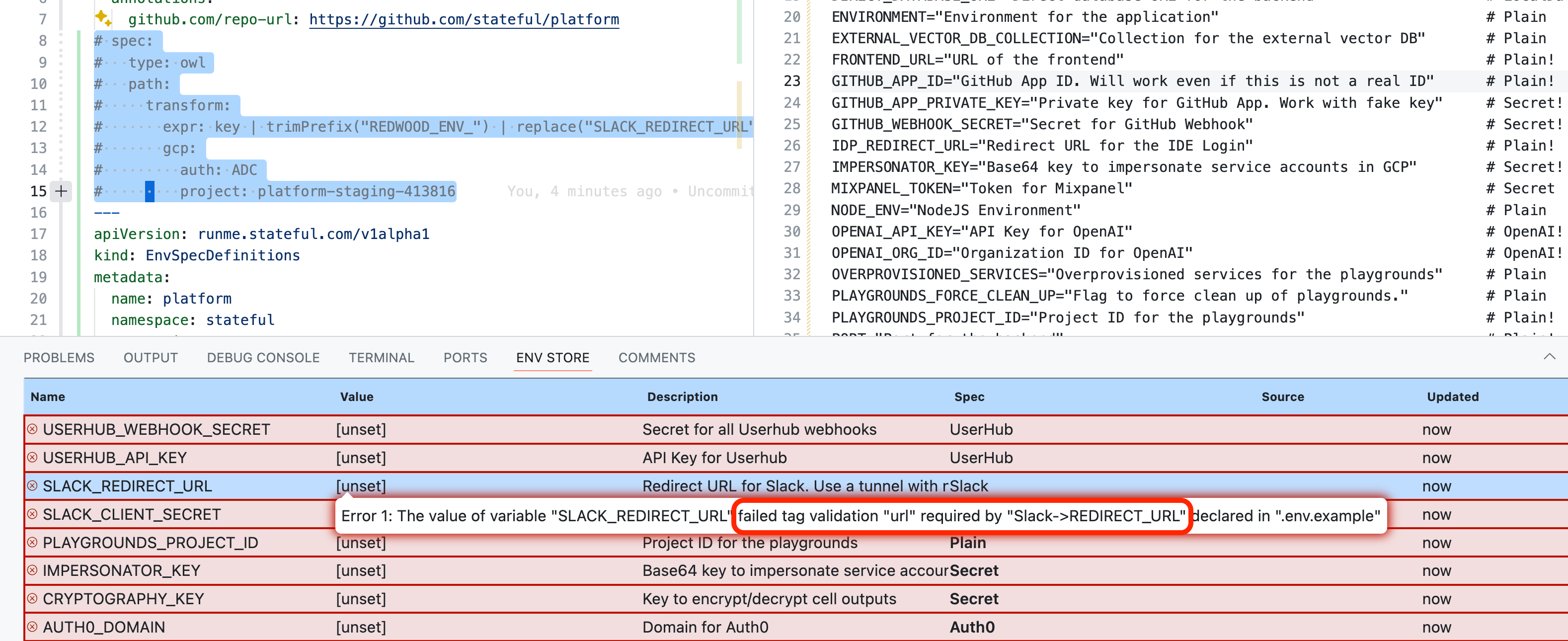
More importantly, it does so securely, making me comfortable publishing screenshots. Concisely identifying the correctness gap in your environment variables is a tremendous boost in help.
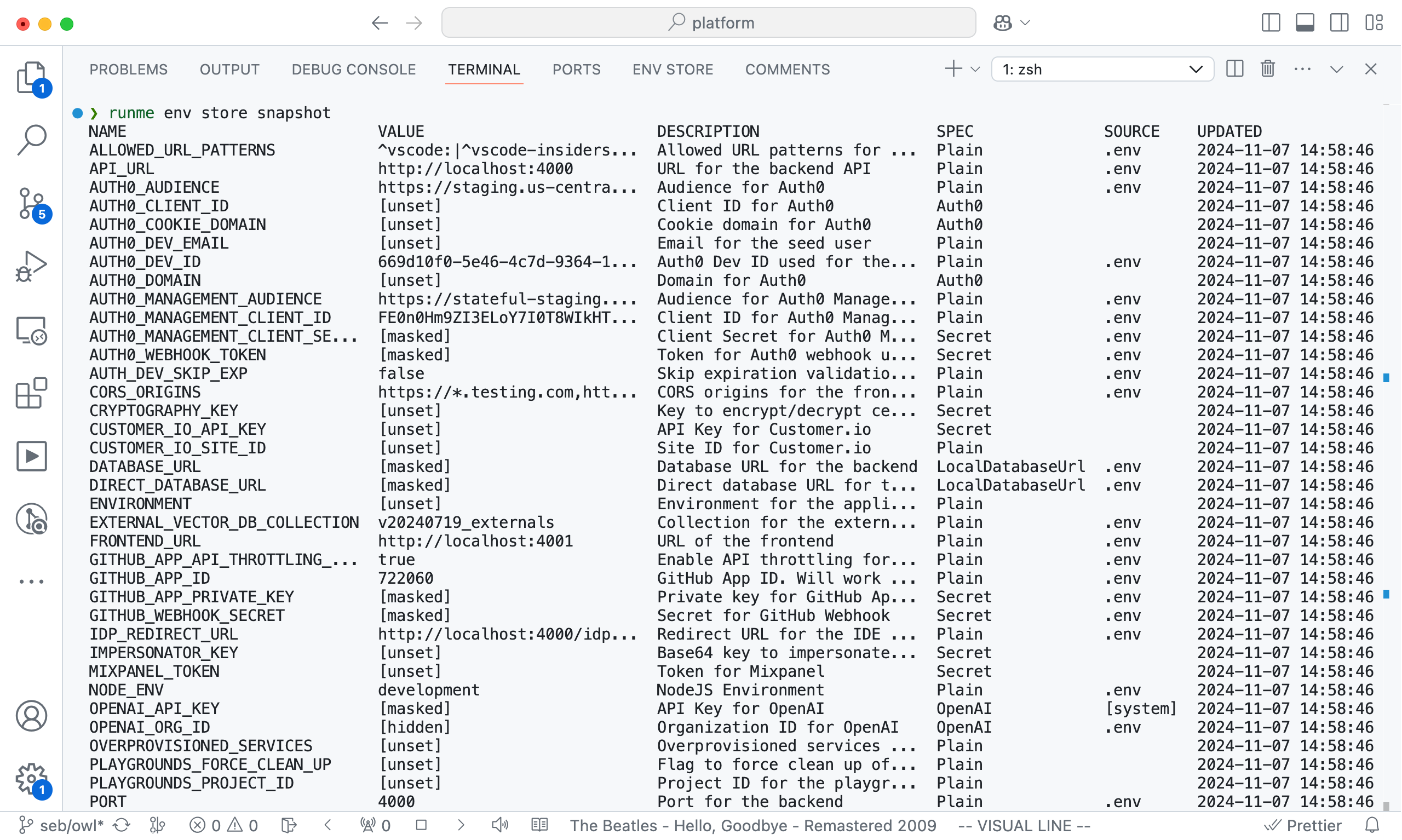
Even better, the Owl’s Env Store UI isn’t locked into a VS Code panel. Thanks to the Owl’s local-only APIs secured by mTLS, the same information is available on the CLI. Looking at this screenshot now, makes me want to color the invalid entries ❌ red. It's on the todo list.
✅ Valid Environment
Now, if your keen eye detected the commented-out resolution path in the upper left editor (above screenshots), let’s return those lines, reset the session (the Owl is a fully managed ENV store), and notice the difference.
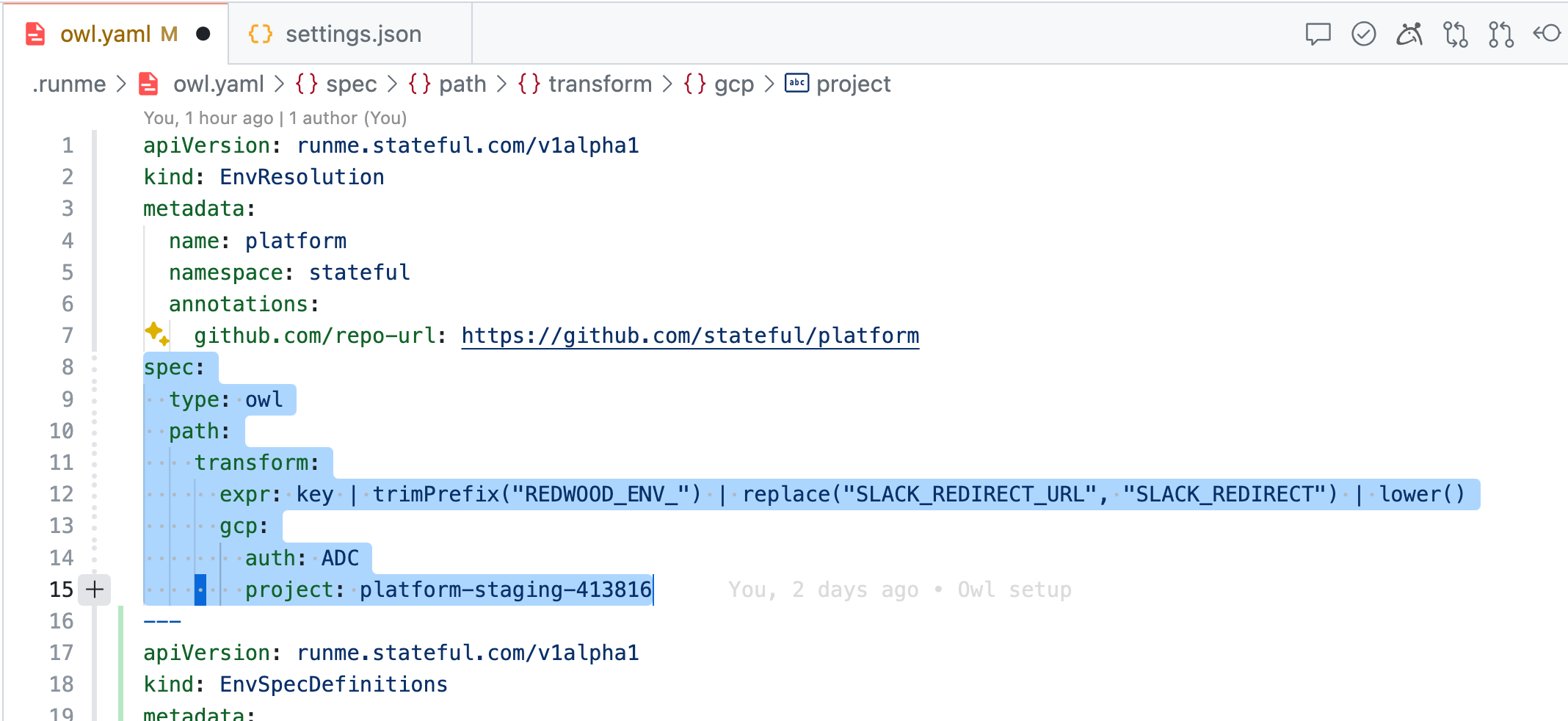
Magic 🧙! Within seconds, there are no more unresolved ENV variables. The Owl Store now automatically resolved variables via GCP’s secret manager (see [gcp:secrets]) using my Application Default Credentials (as in auth: ADC) in the platform-staging-413816 project, which I previously put in place completing GCP’s OAuth flow. It does so quickly by applying simple transformations (see: expr: [...] key | lower()) to the variable keys.
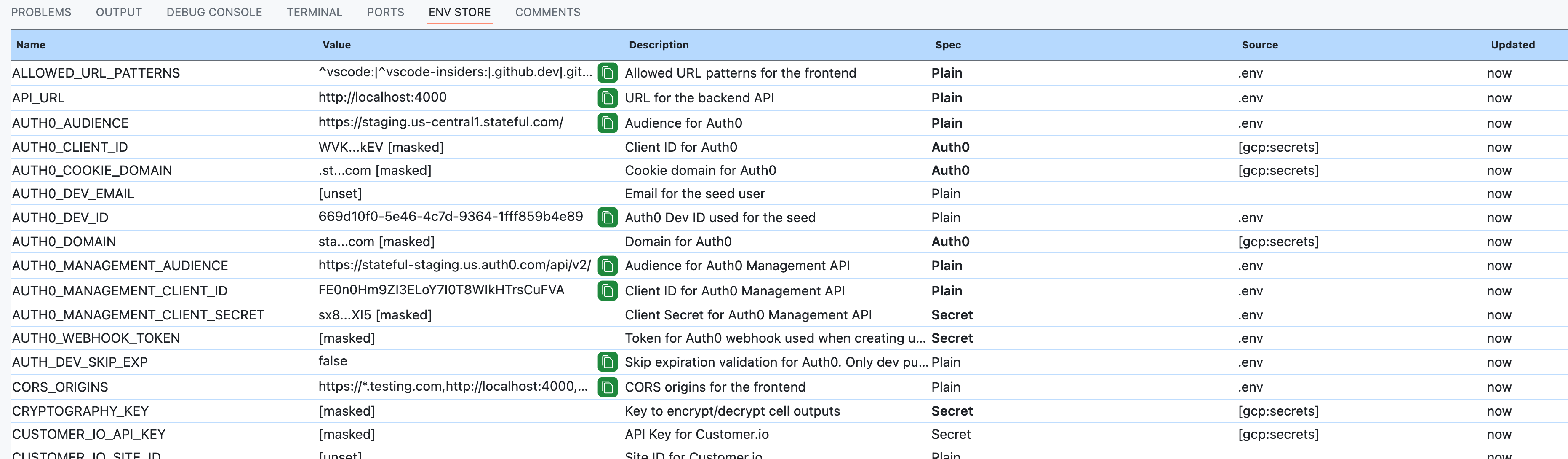
It'd be easy to add triggering GCP's OAuth flow if no valid user credentials are available and/or resolve any other prerequisites that aren't met. Here are a few things to understand. Frankly, GCP's Secret Manager is very much low-hanging fruit. We are using it internally, and it is demoing well. Outside of it, though, AWS, Vault, webhooks, etc., or chaining any of these is possible. There is a lot of ground to cover. However, all the same principles apply.
Desired State: Description of Environment Variables
This example vastly simplifies The Owl Store’s capabilities for demonstration purposes. We chose to reuse DotEnv conventions to meet engineers where they are already.
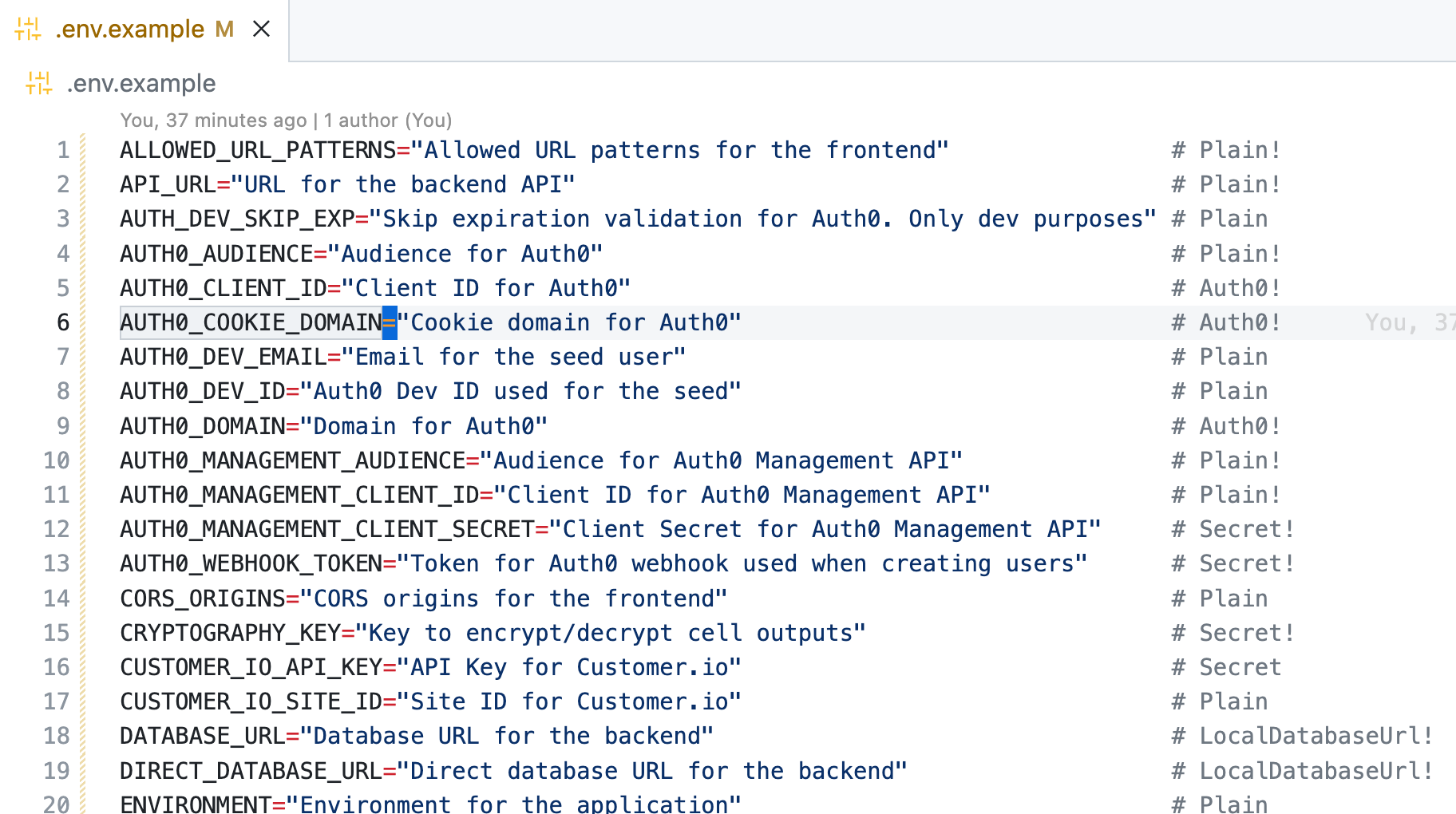
The Owl will look for .env.example, .env.sample, or .env.spec in the code repository's root, which declares the variable’s keys, a description, and an env spec (aka type). This is a slight variation of how .env.example files are already being used, but the payoff is worth the while. We'll debrief this soon.
Flexible Configuration Frontends
In this example, the Owl’s configuration uses a Custom-Resource-Definition-like configuration frontend we usually see in the Kubernetes-world. However, internally the Owl uses a graph representation independent of any configuration frontend. I built the CRDs in a few hours, and they are far from final. Declarative YAML seemed a sensible choice for this example. It would be possible to give Javascript folks a package.json way to do this, Rubyists a DSL, Golang folks a TOML file, or SDKs for any language platform to configure any aspect of the Owl Store. More on this further below.
Multiple Resolution Paths & Mechanisms
In this example, outside of built-in .env. or .env.local resolution (non-sensitive config), the CRD-specified value as per path requires a hard-coded project: platform-staging-413816. However, with the capability of the “rearrangeable” internal graph, it’s possible to have preceding nodes in the graph match a human or workload identity (e.g., GCP user or service-account) to a set of metadata, including project, which downstream is used to resolve secrets in GCP’s secret manager.
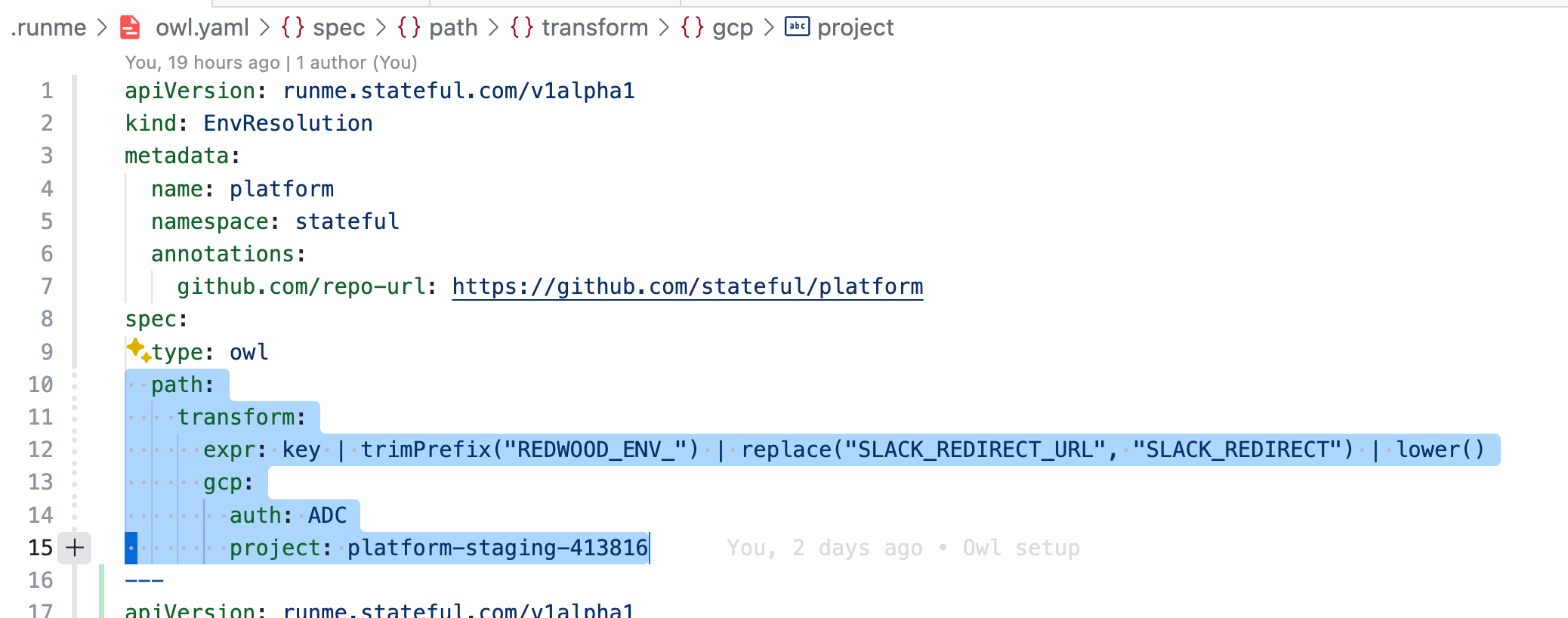
Instead of specifying a single path, running multiple in parallel is possible, and either the one that succeeds first wins or overwrites the other in a defined sequence. It's also possible to consider configuration backends, not just secret managers. What do you need?
Variable Visibility and Validation
Your keen eyes have probably already identified a crucial part of what makes the Owl Store work: Spec Types, e.g., # Secret! Every Variable acquires a type. Unless specified otherwise, it defaults to Opaque, which means it’s neither fully visible nor entirely hidden. One-click reveals the value in the UI. Other atomic spec types are Secret, Password, and Plain. When describing environment variables, you almost always focus on a small yet significant subset. And even without full coverage, secret keys in your shell profile are guarded sufficiently by defaulting to Opaque.
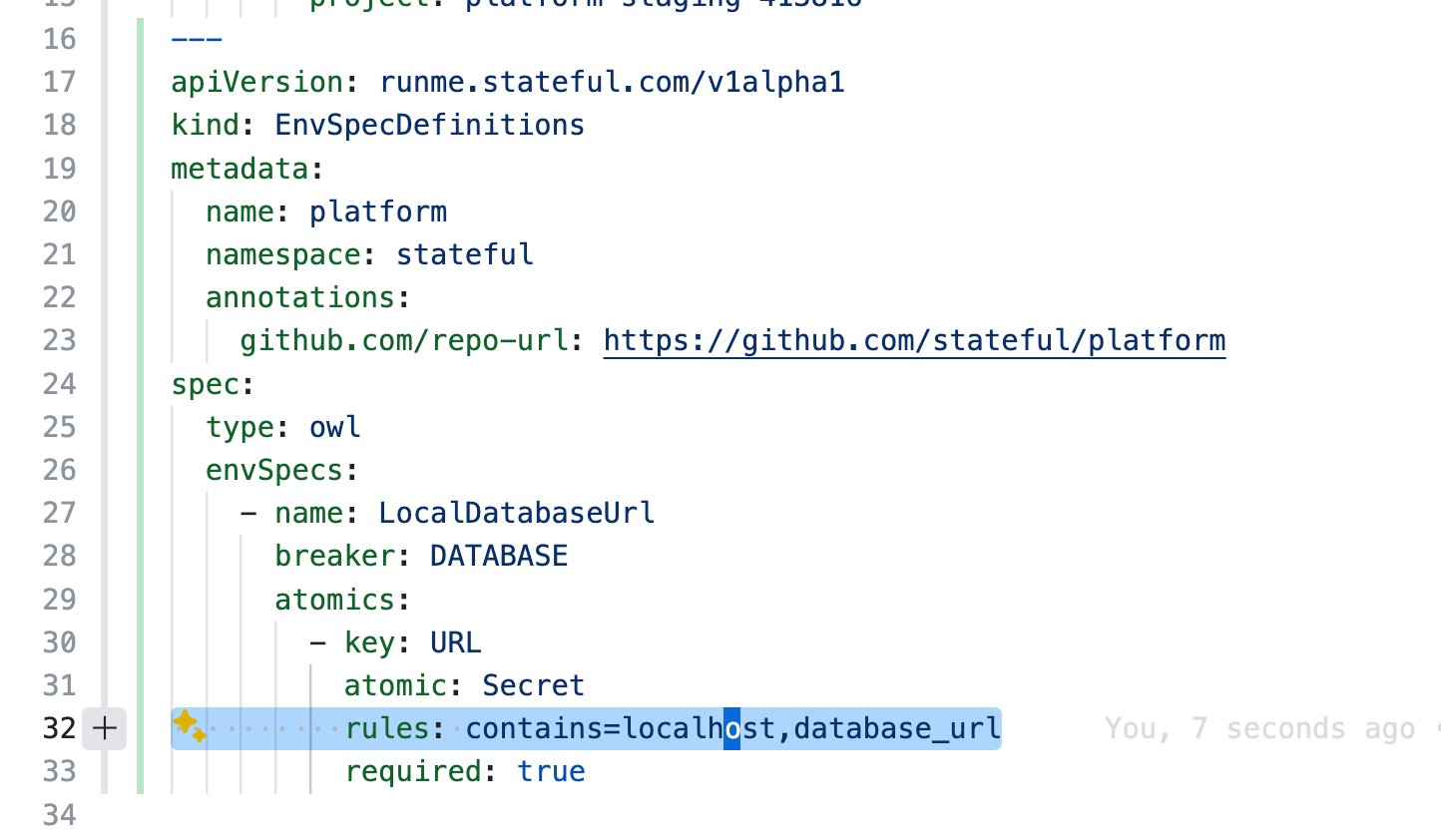
The Spec types Secret and Password are particular. Clear text values are never available in Owl's UI/UX. There is no API to expose them; they are intentionally masked, and the Owl makes no exceptions. Outside of the atomic spec types, it is possible to define custom types to layer validation on top of visibility for built-in security hygiene. More on that below.
Lifecycle over Time
Another detail I wouldn’t want to be overlooked is the Owl Store's Source column. There is a reason why the Owl’s CLI command to inspect the session’s store is called ... store snapshot: An Owl session’s internal graph stores the entire lifecycle of how a single variable is loaded, resolved, verified, mutated, removed, etc., over time.
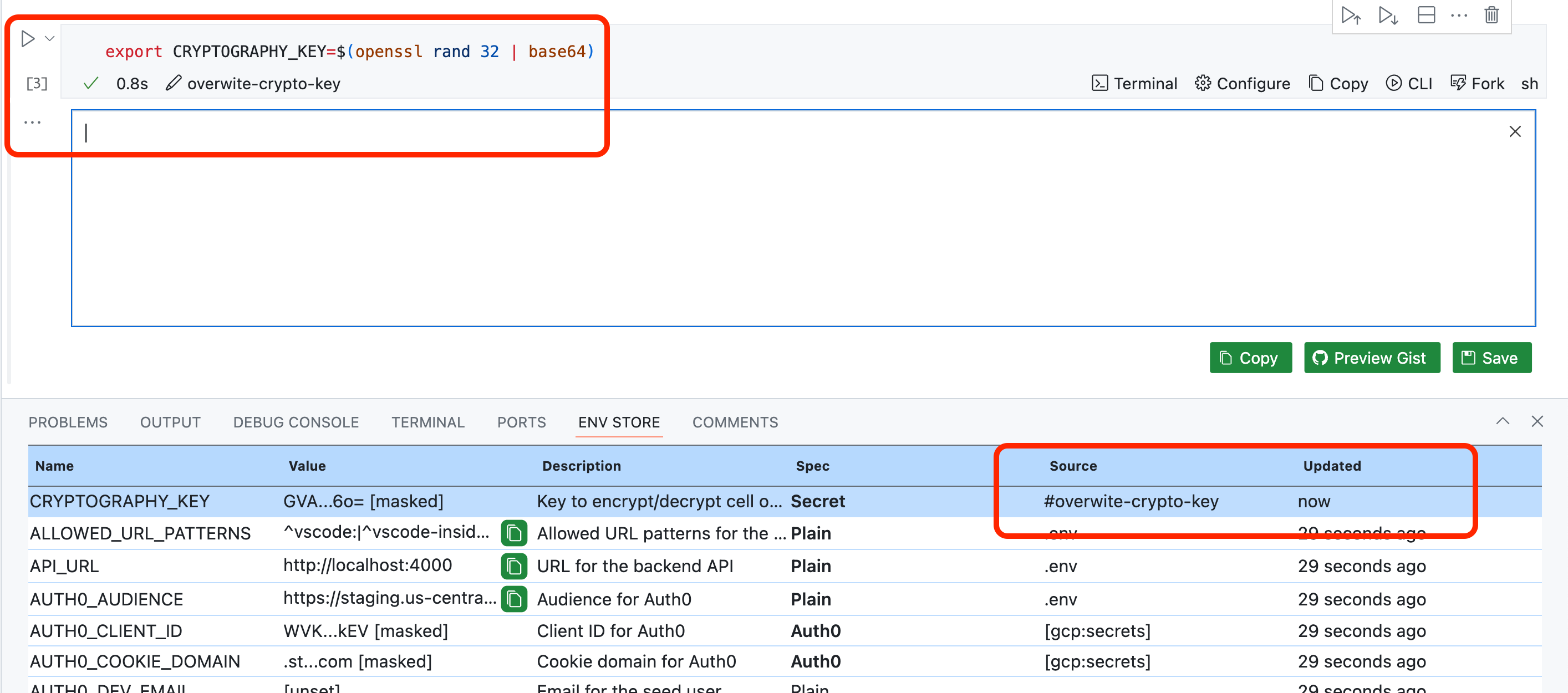
The store’s UI effectively nets a snapshot. The Source column in this UI shows the last recent mechanism that mutated a value. This capability is essential because, unlike workloads, humans are interactive. Occasionally, it makes sense to manually provide the last unresolved value, e.g., the "god password," for the master database.
Interactive Resolution
For instance, a last-resort resolution could be to prompt the user for input when a variable remains unresolved. Runme does precisely that. When it happens, the Owl Store will retain that variable $XYZ was unresolved and transition to resolved when and by what mechanism. Moreover, if you ran unset XYZ in a Runme notebook cell, it would record a deletion.
Of course, if we'd run resolution for a workload, not a human, any variable's unresolved value would be considered an irrecoverable error and exit.
Takeaways
Based on what’s covered in the example above, I will stipulate that Owl’s approach, with human ergonomics first, not just equips it with everything required to configure developer environments but workloads, e.g., CI/CD job, Services running in Kubernetes clusters, too. Running resolution for workloads is a vast simplification since "interactivity" in, e.g., a pipeline makes little sense. Of course, more development effort is required to expand Owl’s graph and integration capabilities to truly unlock this.
I will also claim that Owl’s principles should be extended further up and downstream, e.g., by providing SDKs that, in code, provide type safety while generating Env Spec type declarations instead of maintaining them by hand. Or, Admission Controllers and GitHub Actions that would enable fully reproducing environments anywhere using identity and, at most, an environment identifier, e.g., team5-staging-us-central1. This would make every developer's and operator's life much easier. Win-win!
We need a full-featured tooling ecosystem around “Typed Environments”. The Owl Store 🦉 is precisely that.
Let's look under the hood.
Under the 🦉 Owl Store’s Hood
The Owl Store brings type safety to the 1970s concept of ENV Vars. Remember the skeptics who thought Javascript didn’t need Typescript? Fair enough; don’t use it. The Owl Store is very similar. The Owl in a nutshell:
- A smart Environment Store toolchain for humans and workloads
- Specify, validate, and resolve environment variables anchored in strong identity
- Built-in security hygiene to make the right things easy and the wrong things hard
- Formal verification of “correctness” and opening doors for better tooling ecosystem
- All without requiring remote servers, backend APIs, or taking custody of your secrets
We took inspiration from the SSH Agent and the type system behind Typescript, which brings gradual type safety to Javascript. Despite using it daily, for the longest time, I had no clue how the SSH Agent worked.
In the SSH Agent, once a private key is loaded, the only APIs available are signing, verifying, encrypting, and decrypting messages and signatures. Keys loaded in plain text can not be extracted as such; it's a one-way door. I can’t blame you if you don’t want to know how the SSH Agent works. It just does; you don’t have to. That’s the killer feature.
Skipping a pro/con discussion about strong typing, TypeScript's key feature that inspired us is its ability to be adopted gradually. In the Owl's case, any workload's focus is only ever on a subset of the most important environment variables. Use as much of it as you want—no more, no less.
The Importance of Strong Identity
Anchoring Environments and their resolution on strong human/workload identity (OAuth, workload identity federation, etc.) allows us to decouple from third-party providers. Paired with containers, it makes switching public cloud resource providers (GitHub, AWS, GCP, etc) and/or secret backends (Vault, AWS/GCP Secret Manager, Cloud KMS, etc.) possible, enabling the Owl to stay out-of-band of secrets lifecycles. It unlocks free portability of both human and workload Environments (e.g. my laptop, a CDE in Codespaces, a CI/CD job, Kubernetes clusters running pods).
The closest comparable technology I've seen is Pulumi's ESC. However, it comes from an Infrastructure Management (IaC) angle and mandates Pulumi's proprietary backend. That's not bad per se; it's just different from the Owl Store's principles.
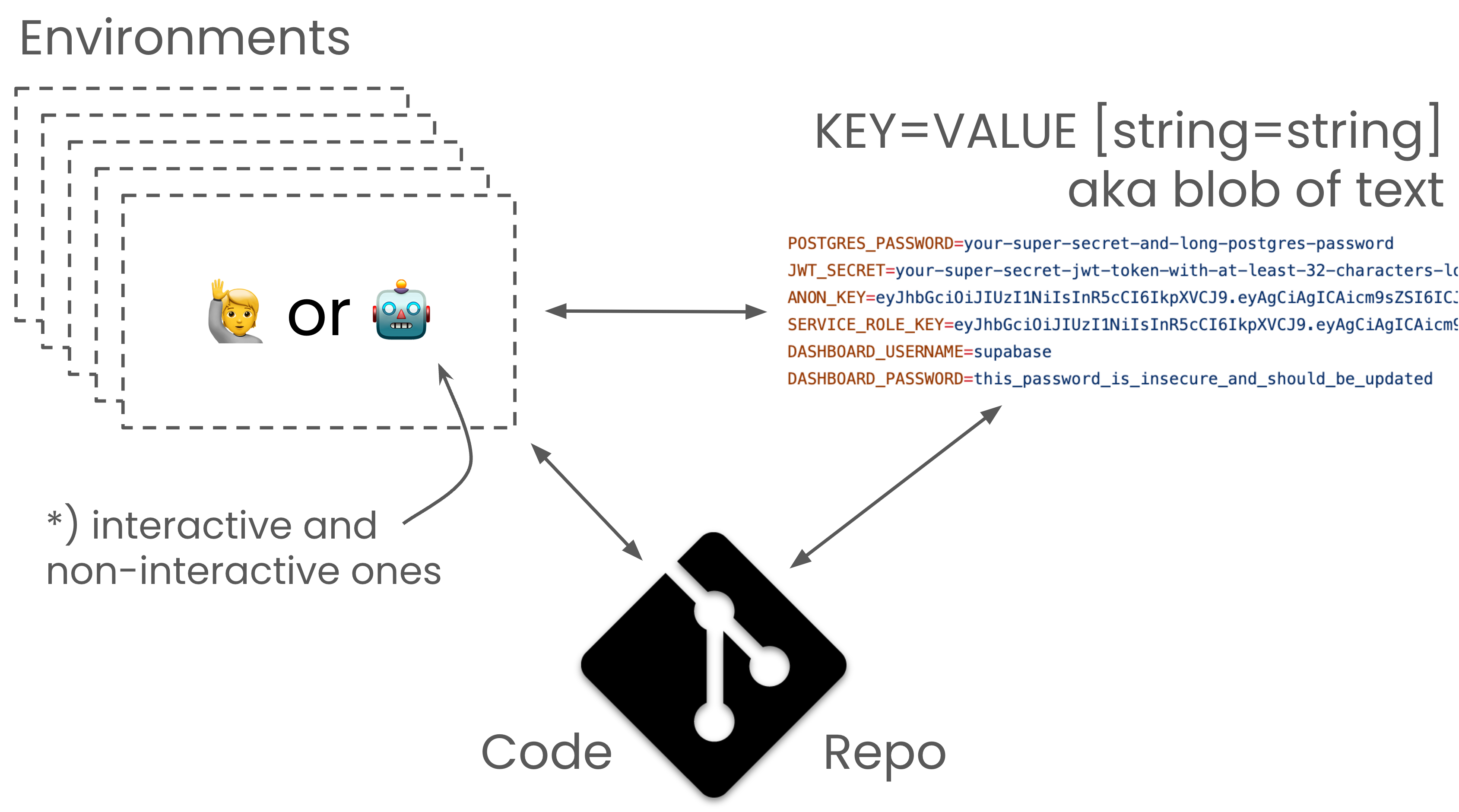
Redefining the Relationship between Workload, Repo, and Environment
Looking at the ordinary lifecycle of any one ENV variable, they start existing by the sheer force of being used. Some programs, workloads/services, and scripts validate better and provide more documentation than others. However, when we are asked to provide values based on blank variable keys, it’s usually left up to the environment and its user. Either you copied the proper values into GitHub/Gitlab, specified them in a Kubernetes/Compose manifest, or had enough -e KEY=VAL in your docker run calls.
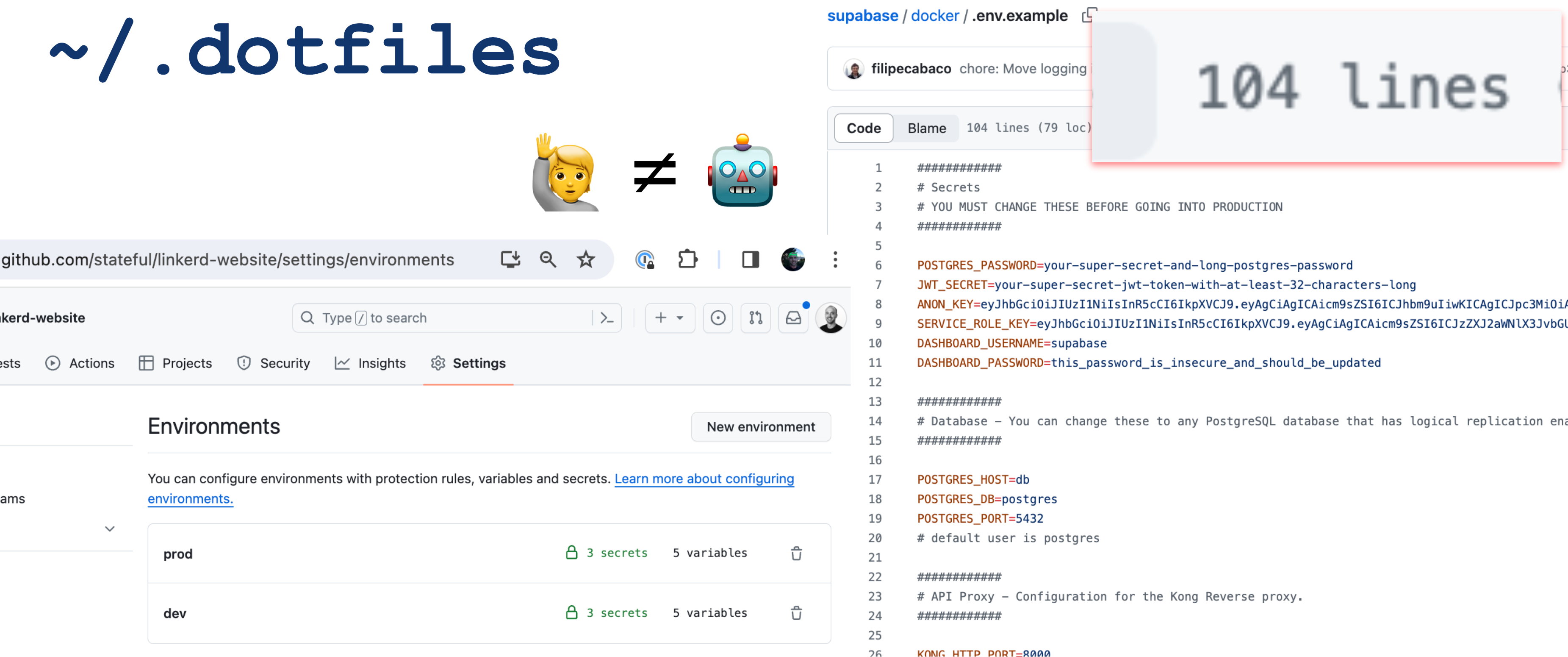
Being a wise bird, the Owl wants a formal description of environment variables to become an essential part of every code repository. Outside of what the Owl does, this would reap the apparent benefits of Git workflows to track the evolution of environment specs.
🦉 This is very important: Without the indirection of a code repository colocated
Environment Specification, we would merely perpetuate the practice of coupling environments to humans (.dotfiles) or workloads (paste config into your pipelines/orchestrators). Docker decoupled app/runtime and system dependencies from machines. Let's finish the job by doing the same for Configuration and Secrets.
Whether or not leaning on .env.example is the best solution here is debatable. However, these files are everywhere and effectively mirror what developers are already doing. And the Owl Store is neutral to how Env Specs are inserted into the graph. Currently, the only implementation is to declare variables in .env.example using spec type annotations. I hope that Copilot or my future bespoke AI model can auto-complete the annotations for you. Optionally, to elevate the importance, one can rename .env.example to .env.spec to send a message that its role has been upgraded.

It’s not inconceivable to allow multiple ways, e.g., a CRD or an SDK, to declare ENV variables and reconcile them on Git pre-push. If ENV access from code used an Owl SDK, it’s not impossible to detect and/or generate missing spec type definitions and declarations accordingly. Better tooling, yay!
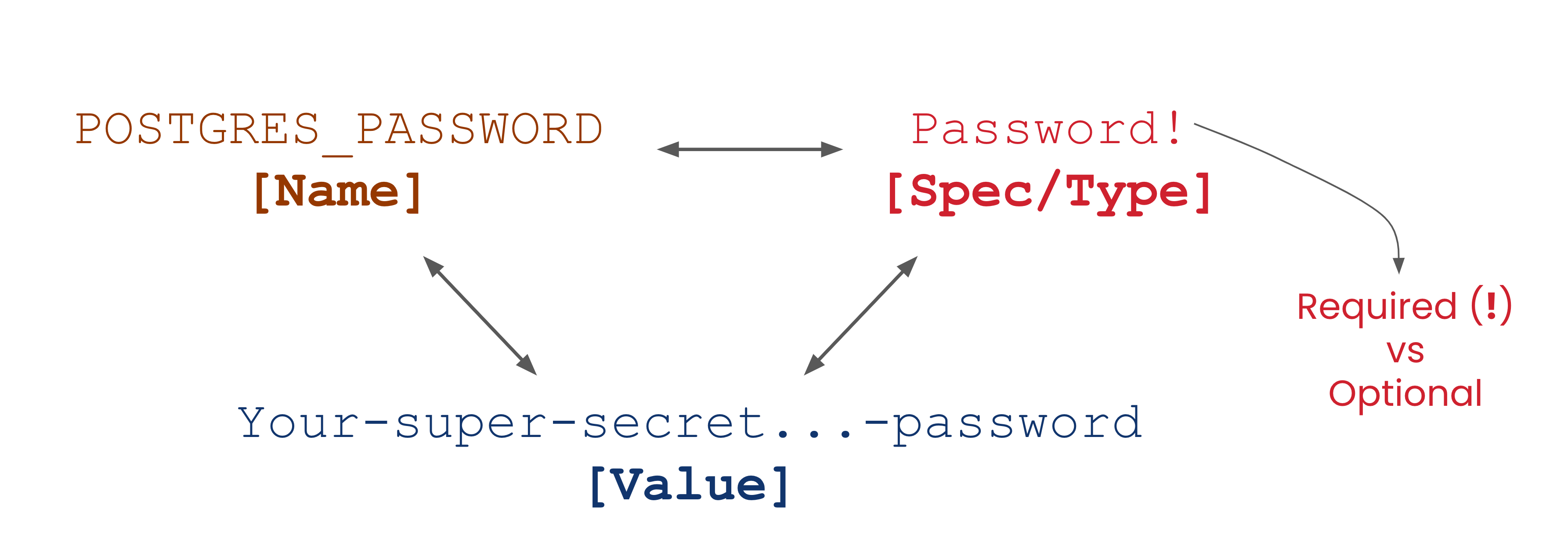
Declare Variables Spec Types via Annotations in .env.example
The anatomy of an environment variable’s Spec type and the resulting triplet is not unusual if you are no stranger to typing. The ! declares variables as required, which will both throw errors when unresolved and consider the variable for resolution (if they aren't Secret or Password). While not final, this is merely an implementation detail and felt suitable for demonstration purposes.
The Owl allows defining Custom Spec types which allow both grouping of atomic variables, e.g. Redis = REDIS_HOST! + REDIS_PORT! + REDIS_PASSWORD, and overlay validation on the atomic-level. E.g. making sure a variable’s value is valid base64, json, jwt, fqdn, etc. To forgo full turing-completeness (security) in validation, Golang's tag validator library and its baked-in tag validators are used. Below are more ideas on how to make validations more powerful and Env Spec types shareable.
By the way, validation is not limited to "compile-time". It’s absolutely conceivable to check, e.g. a connection to a Redis instance, with a single click in the Owl Store UI or TUI. Effectively delivering "runtime" checks on the edge of workloads, services, and scripts. Wouldn’t that be a great feather in the better tooling cap?
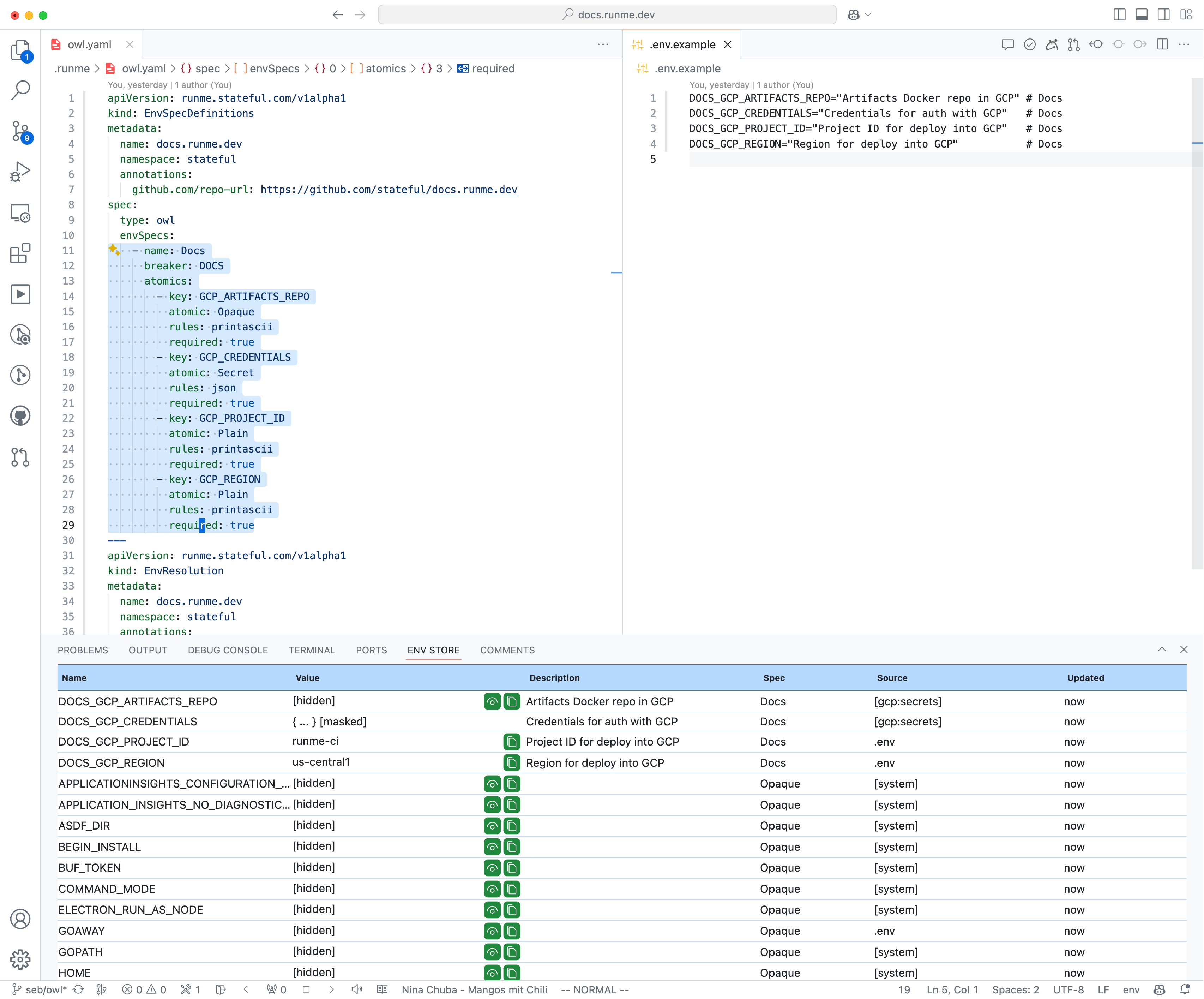
The idea behind these environment variable declarations is simple: Once you have two (name and spec type) out of the triplet, can you find the third? The demo shows this is possible based on contexts like authentication, authorization, metadata, the runtime machine/device/cluster, etc., and running down a resolution path in its respective graph.

Needless to say, it’s powerful to have immediate feedback if a value is absent, invalid, or an error occurs, accompanied by a descriptive error message. Since the Owl Store is fully local, feedback is immediate, making it a perfect fit for an engineer's inner loop while guarding direct access to sensitive values.
The Graph Inside Out 🦉
At the core of the Owl Store is a GraphQL-based graph. Now, forget everything you have ever heard about GraphQL APIs, specifically the latter part. The Owl Store leverages GraphQL for its capabilities to express typed graphs, it’s got an integral type system that transcends the boundaries of language platforms with clients available in every language, and it is battle-tested.
I looked at all sorts of graph libraries, but GraphQL is the only one that checks all the boxes. I even have a rudimentary prototype of the Owl running on React—Preact, to be precise. It just wasn't as language platform neutral, and, let's be honest, how many frontend engineers do you see writing Environment Resolution React components? I'm still not "over" using JSX as a configuration frontend, but even my days only have 24 hours, and again, are people going to use it?
I have to admit what ultimately pushed GraphQL over the edge for me was getting wind of the folks at Dagger pushing forward on using GraphQL for Cloak & Dagger. Wisdom of crowds! I had PoC’d the Owl Store in Javascript’s Apollo first but ultimately decided to implement it inside Runme’s Golang kernel. I'm not a strong Golang developer, so please apply puppy protection to my code. Copilot wrote all the error messages 🤖.
So, if any of what comes next makes no sense to you, that’s totally okay. I won’t stop you from using the Owl Store. We will now look behind the Owl Store's curtains for those interested in the inner workings. I will also skip how Runme gets hold of Environment Variables since the concept of a managed Env Store is integral to Runme's markdown-based notebooks and universal task runner, with or without Owl Store.
GraphQL but no “Data API”
Again, The Owl Store is no GraphQL API. It doesn’t even have a GraphQL endpoint to send queries to. It’s entirely air-gapped and only runs queries programmatically inside the core. Queries are exclusively generated.
Unless you work on the Owl’s core, you never have to look, write, or understand the monstrosity of a serialized query against this graph. If you care about the abstract science behind it, all you need to know is that it works like a massive map-reduce operation where a map of key/specs, key/values, and contextual information such as e.g. GCP auth state is being passed down to every node traversing a query.
The serialized queries (visually fantastic for debugging) grow infinitely to the right since nested nodes execute serially in a predictable sequence. It's just like calling what looks like "infinitely" nested Javascript callbacks. But again, there is no API for human consumption unless you are working on the core.

These queries are monstrous because I decided to err on making the Owl’s graph maximum expressive. For instance, unlike a GraphQL data API where errors usually happen "on the edges" processing data queries or mutations, the Owl store needs to represent “unresolved values” as defined "error states" inside the graph, not as an exception of data ingress or egressing. If an error happens on the GraphQL-level, something more fundamental went wrong, very likely a bug or an unhandled edge case.
Space + Time + Chaining
Space-time blows up the graph's size. The key/value and key/spec maps (not anywhere visible in the serialized queries; passed as GQL variables) can ingress and egress the graph to be fully de/-serialized in between. As mentioned, the Owl Store stores every mutation to ENV vars state and its metadata over time.
This is like double-entry bookkeeping, where you can "net" a snapshot at any given point in time on a timeline. This allows us to answer other questions, such as about the lifecycle of how a variable was used. For instance, if a Runme notebook cell exports a variable export NEW_VAR=123, the Owl Store will store a reference to the respective cell in its metadata.
The capability to egress/ingress the graph makes it possible to chain infinite operations while collapsing the graph state into a snapshot and then ingressing the snapshot into a new graph. The resulting snapshots are virtually identical, and the new graph will no longer have access to previously collapsed history and start writing its own.
A downside, which eventually needs refactoring, is that the GraphQL definitions are relatively simple when using GraphQL types (lots of String no Interfaces, etc.) and have not yet been fully modeled. It's easier to iterate on functionality before going deep on normalization. Strings are easy to de-/serialize.
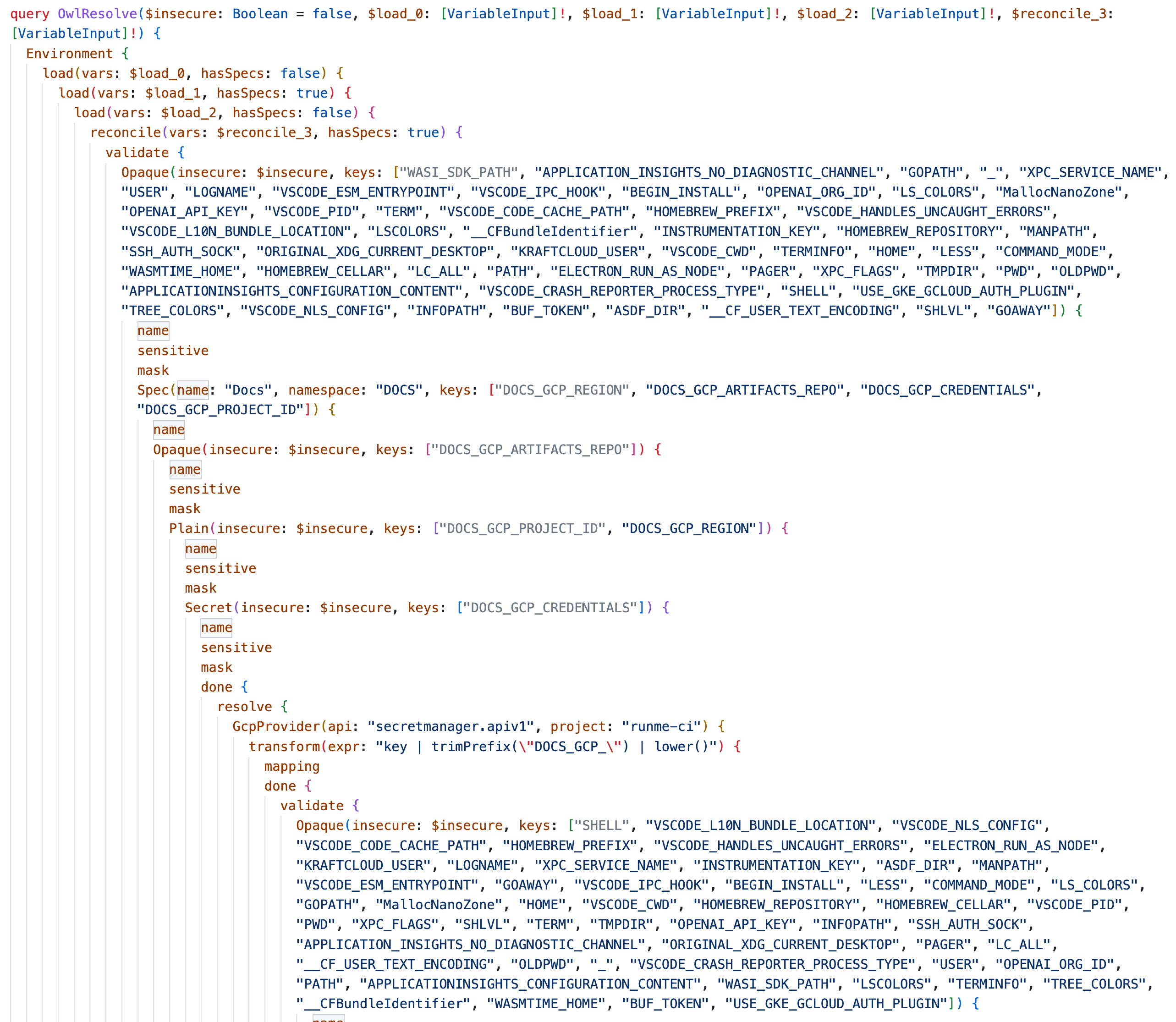
To illustrate how egressing the graph to ingress the snapshot produced into a new graph, let's consider "resolution". Resolution is a query that runs upon constructing a new session and looks very similar to a regular snapshot with running validation twice (before and after) and a few extra nodes in between. Remember, programming the graph is a matter of rearranging its nodes in a different way that’s still valid. It's programmable.
Query Construction & Execution
One aspect of modeling The Owl store around GraphQL fundamentals that’s been tremendously helpful is that it makes it possible to compartmentalize error state into a series of tiny steps and provide high-fidelity error message as opposed to a wholesale bootstrap-all.sh that will attempt to do stand up an environment but randomly exits with error: exit 1 or something similar unhelpful. It’s what I call the AST-fication of complexity into tiny, explainable units.
Remember, no queries in the Owl Store (unless for unit tests), are hand-written. Any query is an output of "mapping and reducing" an input into an output encoding, whether it's a CRD-like YAML or a GraphQL query or GraphQL produces another GraphQL query.

For instance, instead of hard-coding the sequence of how a DotEnv loads, why not express it in a graph where the “client” can easily rearrange the nodes to change its behavior? Any error can be addressed as a distinct "unit of work".
It's not unusual to have GraphQL queries return queries. I suppose what I’m describing here are the benefits of strongly-typed contracts. However, what's uniquely powerful in expressing the Owl Store's capabilities through a graph is a strikingly healthy balance between declarative abstractions and programmability. Anyways, I don't want to bore you.
What's Next
Let us know what you think! The Owl Store is super early. It needs usage and more work to grow into its big promises. Get involved! The owl's code is here. Let's say the code is a bit chaotic. I'm more of a creative who likes solving painful problems than a 10x Golang engineer. Pull Requests are welcome, but more than anything, please try it out!
Here are open questions that are on our minds:
- What do you like? What don't you like?
- What configuration frontends resonate? Declarative, SDKs, Queries?
- Are env spec declarations always the same across all Environments?
- Custom Env Spec type definitions are relatively new and are shoe-horned into the code. Refactor pending!
- We'd love to leverage Cuelang to define Spec types, validate them, and consider sharing via its module system
- Perhaps Cuelang can also play a role in layering overwrites commonplace in env configs?
Get Involved
Whoa, that was a lot.
Again, let us know if any of this interests you. You can find us on Runme’s Discord. Thank you!